Back to Home
Research
How does this YouTube Video Classifier work?
Psychological Background
The psychological impact of thumbnails and titles plays a critical role in shaping viewer behavior on YouTube. Visual features like brightness, edge density, and color contrast capture attention by leveraging principles of visual saliency—our brains are hardwired to notice high-contrast or detailed areas quickly. Titles, meanwhile, trigger cognitive biases through emotional language, urgency, or curiosity—such as in the use of clickbait phrasing or questions—which tap into the psychological phenomenon known as the “curiosity gap.” These elements influence not only whether users notice a video but whether they feel compelled to click, making them central to predicting virality and optimizing content performance before a video is even published.
The visual complexity of an image, as perceived by edge density and local color contrast, increases the likelihood of gaze fixation in the first few milliseconds.
- Nuthmann & Henderson, 2010
Important Feature Genres
Visual Features
- RGB
- Brightness
- Contrast
- Dominant Color Hue
- Thumbnail Edge Density
Text Features
- Sentiment
- Length
- Capitalization/Punctuation
- Clickbait Score
- Readability
Clickbait Score Calculation
def compute_clickbait_score(text: str) -> float:
clickbait_words = {
"amazing", "shocking", "unbelievable", "top", "ultimate", "must",
"insane", "you won’t believe", "secret", "revealed", "hack"
}
words = text.split()
clickbait_score = sum(word.lower() in clickbait_words for word in words)
return clickbait_score;The clickbait score is a simple metric that counts the number of clickbait words in a given text. It can be useful for identifying potentially misleading or sensational content.
Readability Score Calculation
def flesch_reading_ease(text):
sentences = re.split(r'[.!?]+', text)
sentences = [s.strip() for s in sentences if s.strip()]
words = re.findall(r'\w+', text)
num_sentences = max(1, len(sentences))
num_words = max(1, len(words))
num_syllables = sum(count_syllables(word) for word in words)
asl = num_words / num_sentences # Average sentence length
asw = num_syllables / num_words # Average syllables per word
# Flesch Reading Ease formula
score = 206.835 - (1.015 * asl) - (84.6 * asw)
return round(score, 2)The Flesch Reading Ease score is a widely used readability test that evaluates the complexity of English texts. It considers the average sentence length and the average number of syllables per word to produce a score between 0 and 100, where higher scores indicate easier readability.
Training Dataset
The training dataset consists of over 15,000 YouTube videos taken from somewhat popular channels that have been judged by human experts to be "reliant on the YouTube algorithm." This is important to ensure that the model learns from content that is aiming to optimize for virality and engagement, rather than content that performs purely due to an already-established audience or brand. The dataset includes a diverse range of topics and styles, ensuring that the model can generalize well across different types of content.
Training Channels
- French Cooking Academy
- Cooking Buddies
- Glock9
- Phisnom
- BrainCraft
- Jordan Harrod
- Nostalgia Nerd
- EEVblog
- Lainey Ostrom
- Kristin Johns
- iGoBart
- Ghib Ojisan
- Vo2maxProductions
- Heather Robertson
- Alexrainbirdmusic
- Megan Davies
- The Valleyfolk
- Chris Fleming
- Xyla Foxlin
- Potholer54
- Rule1Investing
- Ben Felix
- Griffon Ramsey
- Proko
Model Architecture
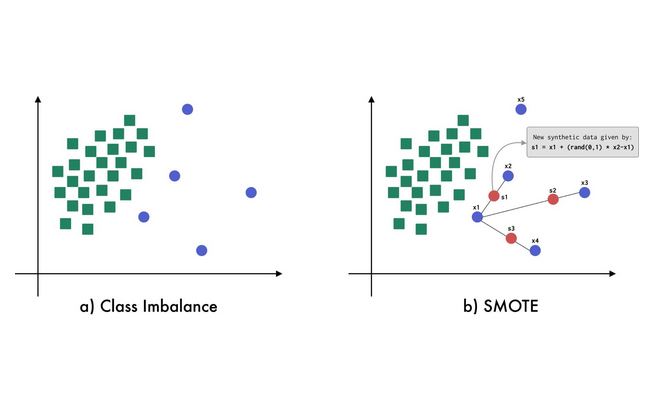
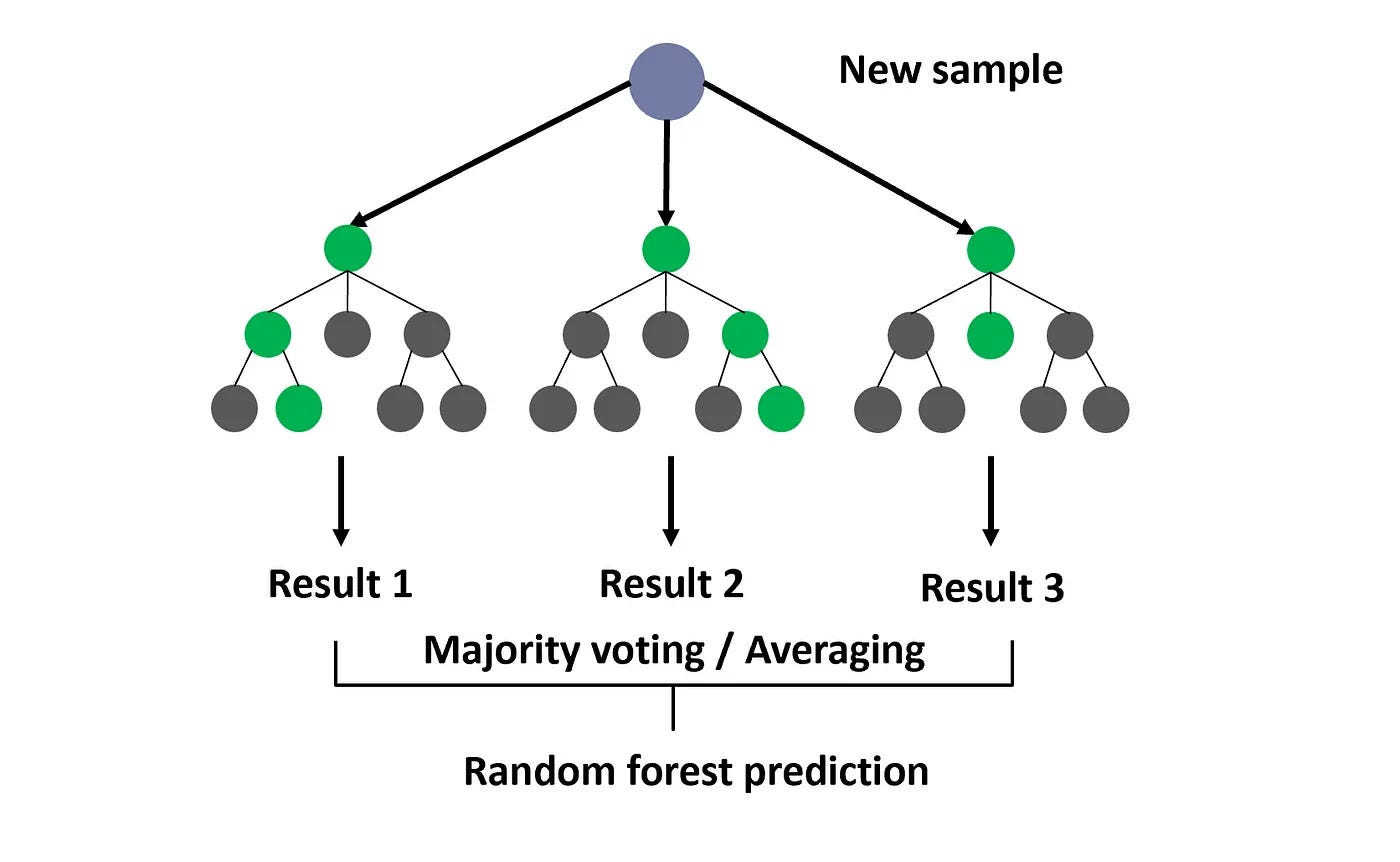
The deployed model powering this web service was trained to recognize patterns in pre-publication metadata that correlate with higher likelihoods of YouTube virality. Unlike models that rely on post-publication signals like early view counts, this system uses only information available before a video is posted—such as title text, description, tags, and thumbnail image—to make its predictions. It leverages a Random Forest classifier enhanced with SMOTE (Synthetic Minority Oversampling Technique) which creates synthetic minority class examples to address class imbalance, ensuring that the model remains sensitive to underrepresented viral examples. By focusing on psychologically and behaviorally relevant features—such as visual salience in thumbnails or curiosity-inducing phrasing in titles—the model supports creators in optimizing their content ahead of time, with minimal technical overhead.
Random Forest Classifier
SMOTE